Tabula is a free tool for extracting data from PDF files into CSV and Excel files. The aim is to liberating data tables locked inside PDF files. Is used to power investigative reporting at news organizations of all sizes, including ProPublica, The Times of London, Foreign Policy, La Nación (Argentina), The New York Times and the St. Paul (MN) Pioneer Press. Grassroots organizations like SchoolCuts.org rely on Tabula to turn clunky documents into human-friendly public resources. And researchers of all kinds use Tabula to turn PDF reports into Excel spreadsheets, CSVs, and JSON files for use in analysis and database applications.
Play with Tabula is dead simple:
Download the version that fit your needs (OS) from the site. i’n my case, i’ve choose the Linux version (but also for other version is the same). The zip file contain a simple Jar file (plus credits, istructions and license files). After running the Jar (with or without the specific launcher) you can point at
http://127.0.0.1:8080
Or
localhost:8080
for the main window.
Note: launching the jar form console often DON’T open the browser automatically.
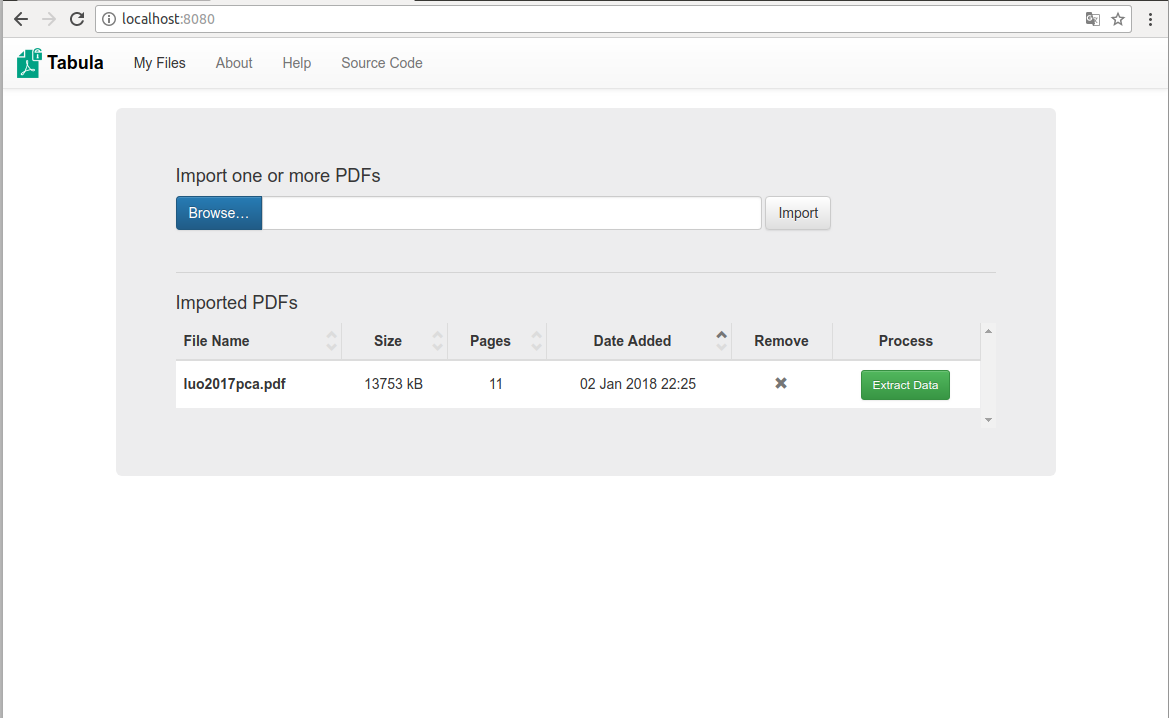
At this point, load the PDF file you want to analyze, selecting it with “Browse” and import it.
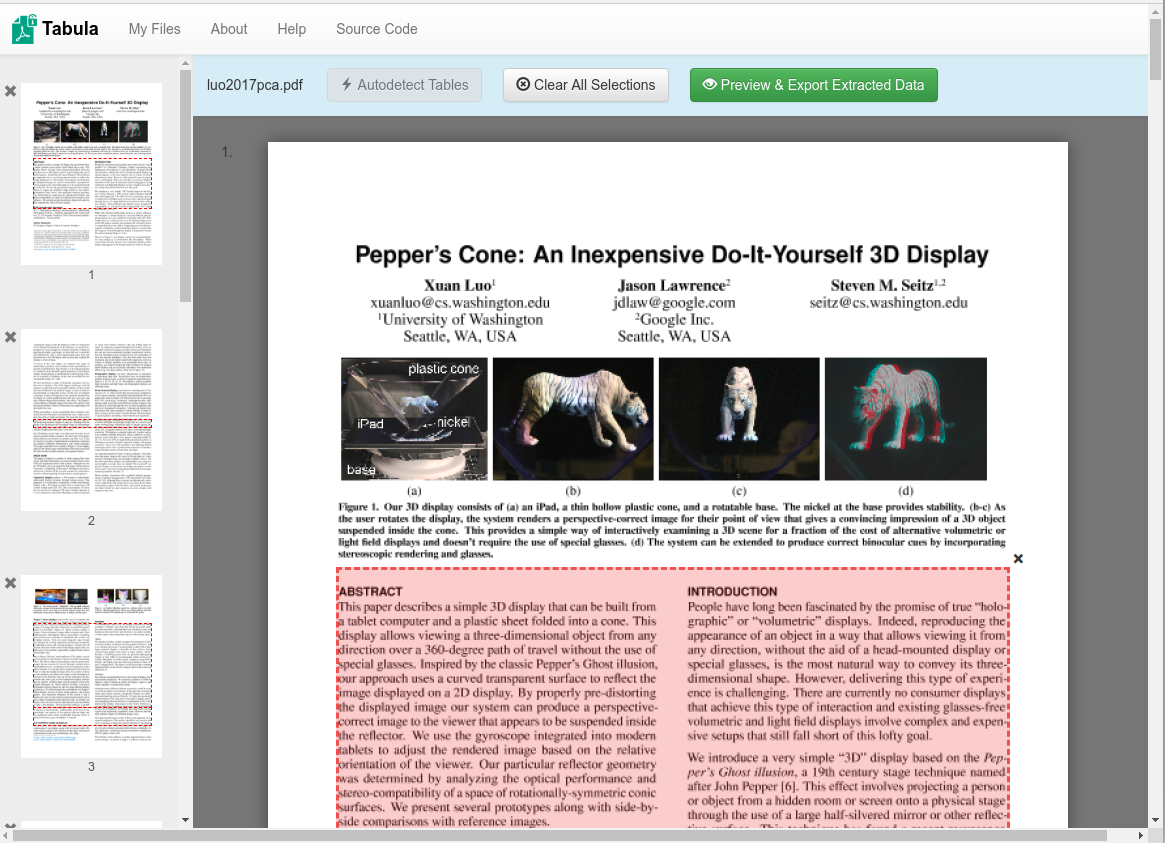
The imported PDF appear in the browser. You can manually select data or try the Autodetect tables.
After manipulating the data you can export results in several formats (CSV, TSV, JSON…)
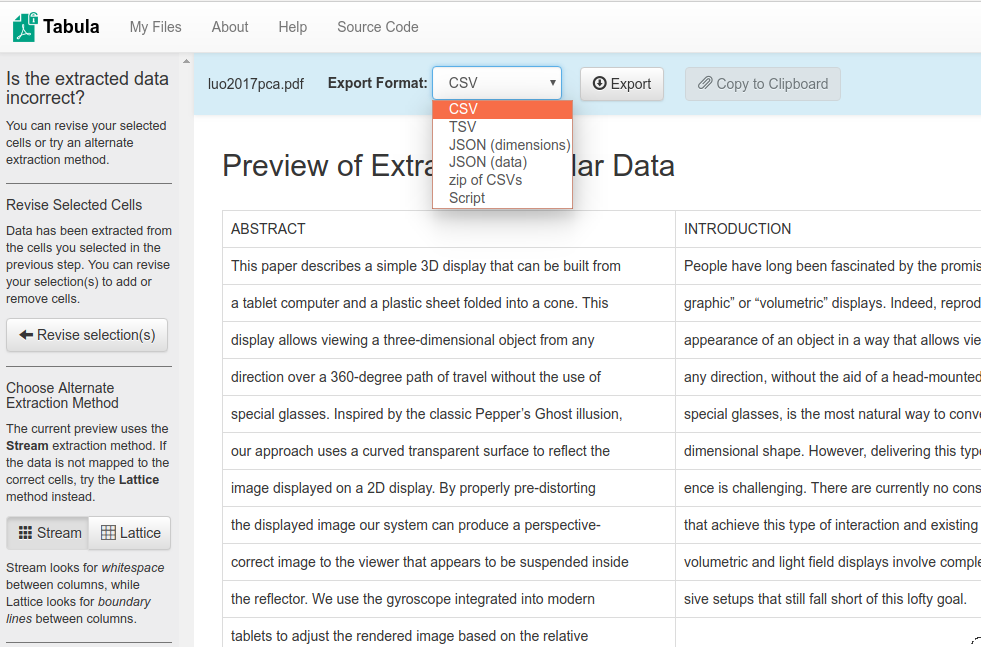
All done!
Tool is free under the MIT Licence
